About me

I am a Research Scientist at Snap Inc. (Creative Vision Team Palo Alto Office) working on Image and Video Personalization. I was a postdoc at Stanford Computational Imaging Lab, Stanford University working with Prof. Gordon Wetzstein. I completed my Ph.D. in Computer Science at VCC, KAUST, supervised by Prof. Peter Wonka. I worked closely with Prof. Niloy Mitra (UCL and Adobe Research). Before that, I obtained the MS Computer Science degree from KAUST, and the B.Tech degree from National Institute of Technology (NIT), Srinagar, India. My work focuses on creating personalized content that captures unique user expressions, motions, and interactions in immersive and collaborative environments. We are looking for Interns. Feel free to reach out to me directly.
You can find my full CV here.
Education and Training
 Postdoc at SCI Lab
Postdoc at SCI Lab
Stanford University
2023 - 2024
![]() Ph.D. in Computer Science
Ph.D. in Computer Science
KAUST, Visual Computing Center
2020 - 2023
![]() MS in Computer Science
MS in Computer Science
KAUST, Visual Computing Center
2018 - 2020
 B.Tech in ECE
B.Tech in ECE
NIT Srinagar
2014 - 2018
Research Experience
 Snap Inc.
Snap Inc.
Research Scientist, Palo Alto, California, USA
September 2024 - present
Snap Research
Research Intern @ Creative Vision, Los Angeles, California, USA
June 2022 - Oct 2022
 Adobe Research
Adobe Research
Collaborator (Remote), London, UK
March 2020 - May 2022
Publications
2026
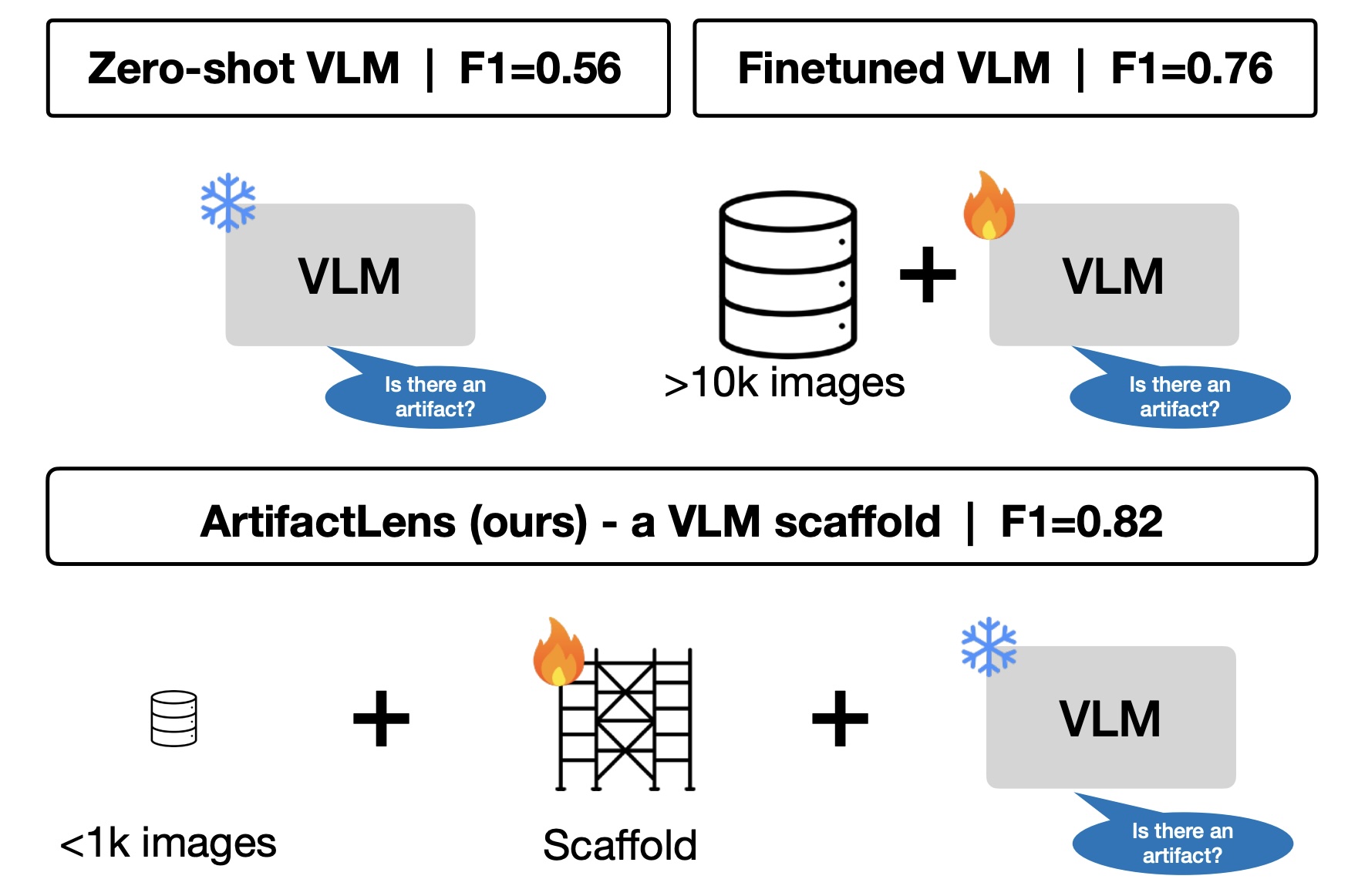
ArtifactLens: Hundreds of Labels Are Enough for Artifact Detection with VLMs
James Burgess,
Rameen Abdal,
Dan Stoddart,
Sergey Tulyakov,
Serena Yeung-Levy,
Kuan-Chieh Jackson Wang
Stanford University, Snap Research
arXiv 2026
paper
Project Page
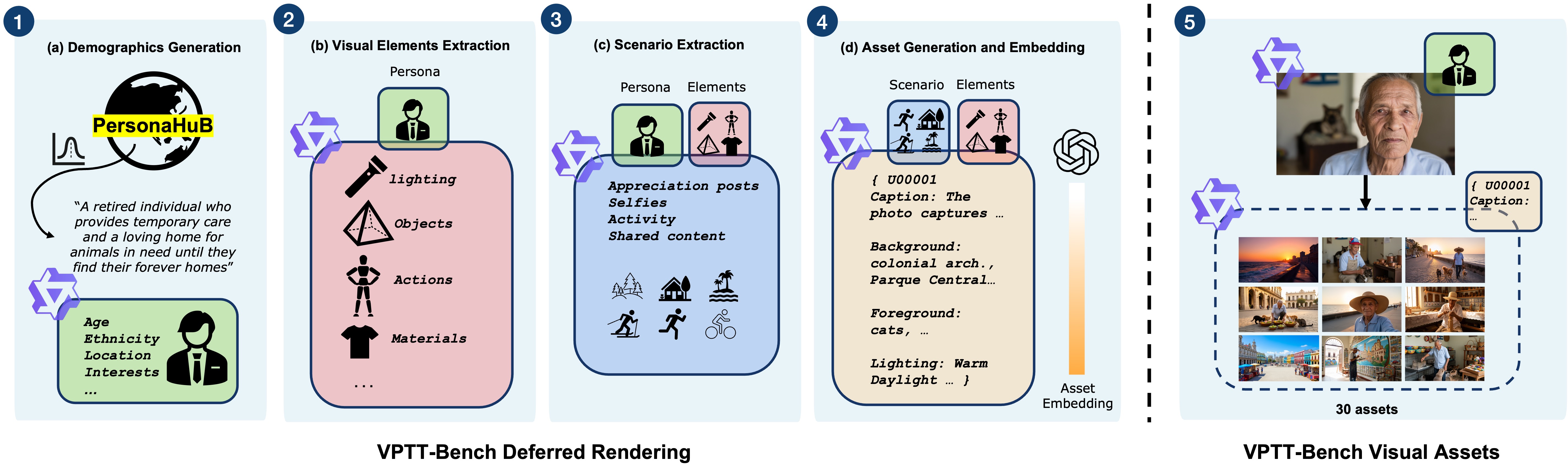
Visual Personalization Turing Test
Rameen Abdal,
James Burgess,
Sergey Tulyakov,
Kuan-Chieh Jackson Wang
Snap Research, Stanford University
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
paper
Project Page
Tuning-free Visual Effect Transfer across Videos
Maxwell Jones,
Rameen Abdal,
Or Patashnik,
Ruslan Salakhutdinov,
Sergey Tulyakov,
Jun-Yan Zhu,
Kuan-Chieh Jackson Wang
Carnegie Mellon University (CMU), Snap Research
arXiv 2026
paper
Project Page

2023 - 2025
Zero-Shot Dynamic Concept Personalization with Grid-Based LoRA
Rameen Abdal,
Or Patashnik,
Ekaterina Deyneka,
Hao Chen,
Aliaksandr Siarohin,
Sergey Tulyakov,
Daniel Cohen-Or,
Kfir Aberman
Snap Research
SIGGRAPH Asia, 2025
paper
Project Page
Video

Dynamic Concepts Personalization from Single Videos
Rameen Abdal,
Or Patashnik,
Ivan Skorokhodov,
Willi Menapace,
Aliaksandr Siarohin,
Sergey Tulyakov,
Daniel Cohen-Or,
Kfir Aberman
Snap Research
SIGGRAPH, 2025
paper
Project Page
Video
Siggraph Trailer

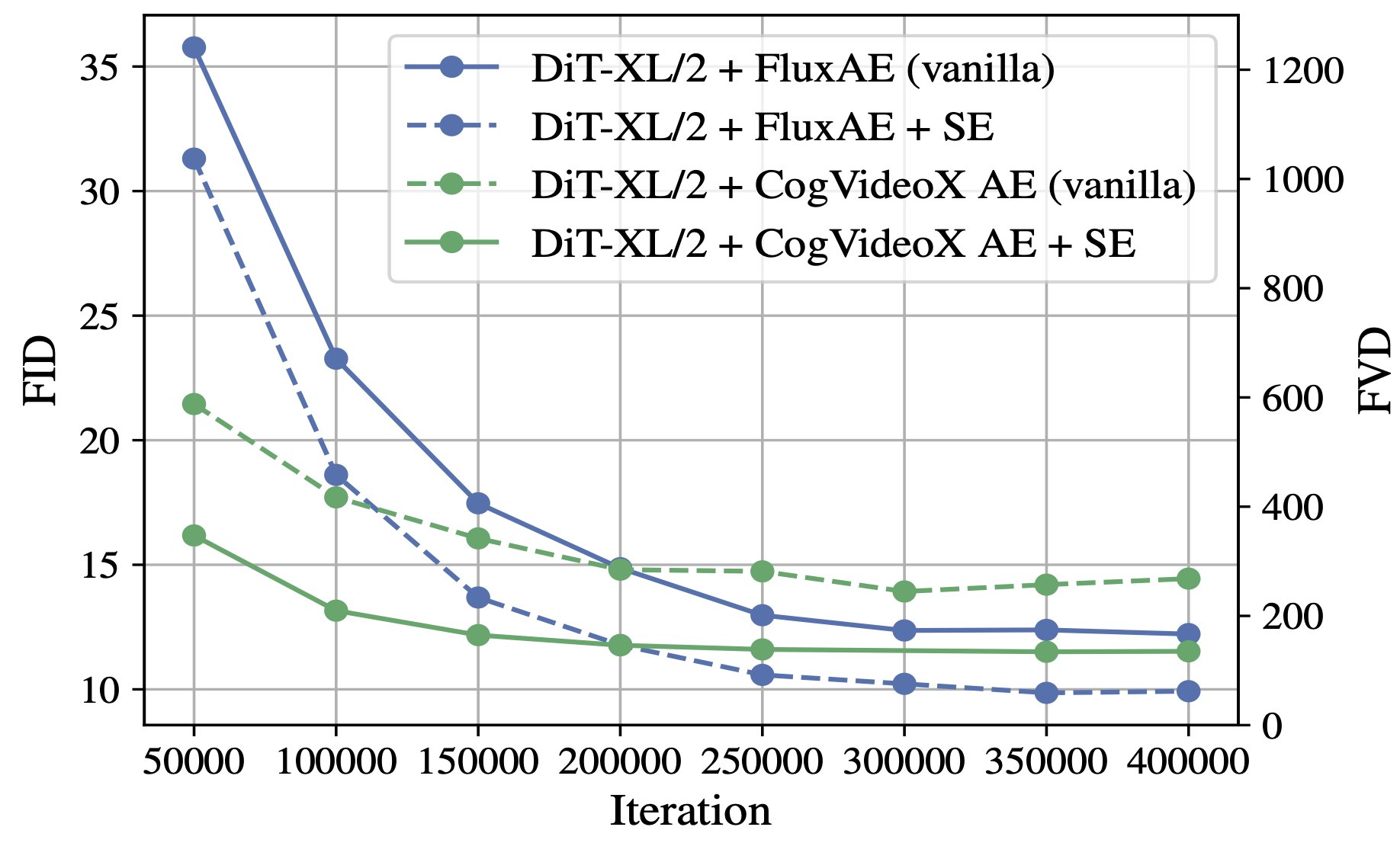
Improving the Diffusability of Autoencoders
Ivan Skorokhodov,
Sharath Girish,
Benran Hu,
Willi Menapace,
Yanyu Li,
Rameen Abdal,
Sergey Tulyakov,
Aliaksandr Siarohin
Snap Research, Carnegie Mellon University (CMU)
ICML, 2025
paper
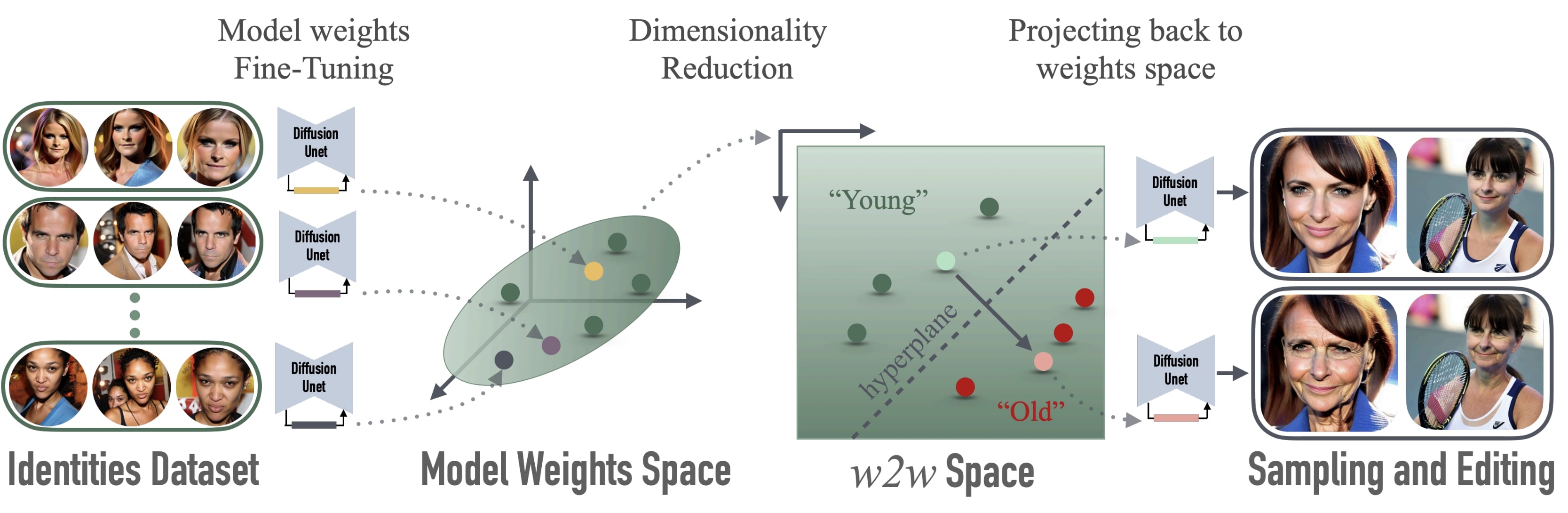
Interpreting the Weight Space of Customized Diffusion Models
Amil Dravid,
Yossi Gandelsman,
Kuan-Chieh Wang,
Rameen Abdal,
Gordon Wetzstein,
Alexei A. Efros,
Kfir Aberman
Snap Research, Stanford University, University of California Berkeley
NeurIPS 2024
paper
suppl.
Gaussian Shell Maps for Efficient 3D Human Generation
Rameen Abdal*,
Wang Yifan*,
Zifan Shi*,
Yinghao Xu,
Ryan Po,
Zhengfei Kuang,
Qifeng Chen,
Dit-Yan Yeung,
Gordon Wetzstein
Stanford University, HKUST
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
paper
suppl.

3DAvatarGAN: Bridging Domains for Personalized Editable Avatars
Rameen Abdal,
Hsin-Ying Lee,
Peihao Zhu,
Menglei Chai,
Aliaksandr Siarohin,
Peter Wonka,
Sergey Tulyakov
KAUST, Snap Research
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
paper
suppl.
2022
Video2StyleGAN: Disentangling Local and Global Variations in a Video
Rameen Abdal,
Peihao Zhu,
Niloy J. Mitra,
Peter Wonka
ArXiv pre-print, 2022
KAUST, UCL, Adobe
paper
suppl.

HairNet: Hairstyle Transfer with Pose Changes
Peihao Zhu,
Rameen Abdal,
John Femiani,
Peter Wonka
KAUST, Miami University
Proc. European Conference on Computer Vision (ECCV), 2022
paper
suppl.
CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions
Rameen Abdal,
Peihao Zhu,
John Femiani,
Niloy J. Mitra,
Peter Wonka
KAUST, Adobe, UCL, Miami University
ACM SIGGRAPH Conference Proceedings, 2022 (Selected for Lab Demo)
paper
code
suppl.

Mind the Gap: Domain Gap Control for Single Shot Domain Adaptation for Generative Adversarial Networks
Peihao Zhu,
Rameen Abdal,
John Femiani,
Peter Wonka
KAUST, Miami University
International Conference on Learning Representations (ICLR), 2022
paper
code
suppl.

2021
Barbershop: GAN-based Image Compositing using Segmentation Masks
Peihao Zhu,
Rameen Abdal,
John Femiani,
Peter Wonka
KAUST, Miami University
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 2021
paper
code
suppl.
Two Minute Papers

StyleFlow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows
Rameen Abdal,
Peihao Zhu,
Niloy J. Mitra,
Peter Wonka
KAUST, UCL, Adobe
ACM Transactions on Graphics (TOG), 2021
paper
code
suppl.
Two Minute Papers

Labels4Free: Unsupervised Segmentation using StyleGAN
Rameen Abdal,
Peihao Zhu,
Niloy J. Mitra,
Peter Wonka
KAUST, UCL, Adobe
Proc. IEEE International Conference on Computer Vision (ICCV), 2021
paper
code
suppl.

2020
SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
Peihao Zhu,
Rameen Abdal,
Yipeng Qin,
Peter Wonka
KAUST
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR Oral), 2020
paper
code
suppl.

Image2StyleGAN++: How to Edit the Embedded Images?
Rameen Abdal,
Yipeng Qin,
Peter Wonka
KAUST
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
paper
suppl.

2019
Image2StyleGAN: How to Embed Images into the StyleGAN Latent Space?
Rameen Abdal,
Yipeng Qin,
Peter Wonka
KAUST
Proc. IEEE International Conference on Computer Vision (ICCV Oral), 2019
paper
suppl.

Patents
Avatar Generation According To Artistic Styles
Rameen Abdal, Menglei Chai, Hsin-Ying Lee, Aliaksandr Siarohin, Sergey Tulyakov, Peihao Zhu
US Patent
link
Attibute Conditioned Image Generation
Rameen Abdal, Niloy Mitra, Peter Wonka, Peihao Zhu
US Patent (US 16934858), 2022
link
Committee and Reviewer
SIGGRAPH ASIA 25, 26 (TPC) | SIGGRAPH 26 (TPC) | EUROGRAPHICS 24 (IPC) | ICML 2024 | TOG | TVCG | TPAMI | AAAI 22-24 | NEURIPS 23-25 | ICLR 24-26 | CVPR 21-25 | ICCV 21/23/25 | ECCV 22/24/26 | SIGGRAPH 21-25 | SIGGRAPH ASIA 21-24
Talks
Stanford Computational Imaging Lab, 2022
EXTRACTING SEMANTICS, GEOMETRY, AND APPEARANCE USING GANS
Stanford University, USA
Rising Stars in AI Symposium (organized by Jurgen Schmidhuber), 2022
EXTRACTING SEMANTICS, GEOMETRY, AND APPEARANCE USING GANS
KAUST, KSA
Adobe Research, 2022
EXTRACTING SEMANTICS, GEOMETRY, AND APPEARANCE USING STYLEGAN
San Jose, USA
Ethics and Social Impact
The advancements in generative AI, including personalized video generation, bring remarkable opportunities for creativity, education, entertainment, and other constructive applications. However, these capabilities also come with ethical challenges that must be acknowledged. The potential misuse of this technology to create deepfakes, manipulate identities, or generate misleading content is a serious concern. In our work, we use celebrity images/ video footage strictly under the fair use doctrine i.e. exclusively for purposes of research, commentary, and analysis. Additionally, biases inherent in generative models might result in unfair or stereotypical representations, further emphasizing the need for responsible development and deployment practices. We strongly emphasize that such technology must be used ethically and responsibly. As researchers, we do not condone any misuse of generative AI for malicious purposes, including spreading misinformation or creating harmful content. Instead, we advocate for its application in areas like education, storytelling, virtual production, and accessibility.
Contact
Address
Palo Alto
Email
rameen.abdal@gmail.com
rabdal@snap.com